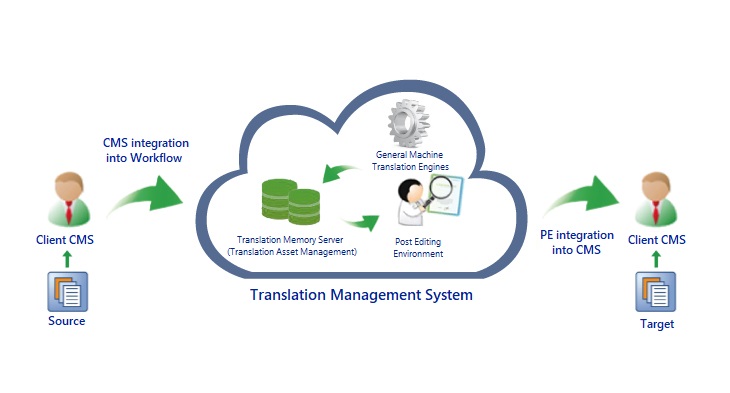
Un processus simplifié
À la demande de notre client et en fonction de ses spécifications, nous intégrerons une solution de traduction automatique de référence à notre processus de contrôle qualité pour produire des traductions extrêmement fiables et précises. Il a été démontré que ce processus exclusif améliore considérablement les délais d’exécution et réduit les coûts tout en maintenant un très haut niveau de qualité de traduction.
Moteurs de traduction automatique généralistes
Un moteur de traduction automatique généraliste (parfois appelé « MTAG ») désigne un logiciel capable de traduire un texte vers et depuis une langue donnée avec une intervention humaine mineure ou nulle. Bien que ces moteurs de référence soient construits différemment, la plupart d’entre eux sont conçus pour traduire un contenu général n’impliquant pas de terminologie spécialisée, d’où le nom de solutions de traduction automatique généralistes. Les plus populaires sont Google Translate, Systran, Microsoft Translator, Microsoft Hub et Amazon.
Pour la compréhension globale d’un contenu relativement basique, les moteurs de base peuvent faire un travail satisfaisant. Cependant, à ce jour, les moteurs personnalisés ont toujours un avantage concurrentiel. C’est-à-dire que les traductions produites par les seuls MTAG ne sont pas suffisamment fiables pour un usage professionnel, car les erreurs sont inévitables même pour des documents simples.
Cela dit, un MTAG peut être un élément utile du processus de traduction, en fonction des objectifs du client et de la nature du projet. Chez Trusted Translations, nous avons appris à tirer parti des MTAG et à les intégrer en fonction des besoins et des objectifs de nos clients. Si nous pensons qu’un certain projet est un bon candidat pour intégrer des MTAG au processus, nous discutons de cette option avec notre client et concevons une solution qui combine tous les avantages des MTAG, des serveurs de mémoire ainsi que de la traduction humaine (HT) et de la révision.
Serveurs de mémoires de traduction et traductions automatiques généralistes
L’utilisation d’un serveur de mémoire de traduction (« SMT ») lorsque l’on a recours à un MTAG est un moyen d’améliorer la qualité globale du résultat de la traduction, car il exploite les segments existants traduits par l’homme comme éléments de la traduction. L’utilisation de ce type de contenu existant permet de garantir la qualité, ce qui se traduit par une meilleure fidélité aux directives de style spécifiques au client, et peut même constituer une aide terminologique dans les cas où les glossaires ne sont pas un atout majeur. Une configuration possible du flux de travail pour la préparation du contenu consisterait à traduire d’abord chaque segment de contenu au moyen d’un SMT. Si aucun segment identique ou similaire (correspondance complète ou approximative – « full match » ou « fuzzy match ») n’est trouvé lors de cette première étape, le contenu est alors transmis au moteur de traduction automatique généraliste.
La plupart des SMT vous permettent actuellement d’effectuer ces deux étapes simultanément. Enfin, le contenu bilingue, généré soit à partir d’une mémoire de traduction soit à partir d’une traduction automatique pure, peut également être édité par un post-éditeur expert, c’est-à-dire un linguiste spécialement formé pour travailler sur les traductions générées par des mémoires de traduction. Par la suite, toutes les post-éditions humaines seront réintroduites dans le SMT, ce qui améliorera la qualité de la prochaine traduction.
Post-édition humaine des traductions automatiques généralistes
L’utilisation de MTAG peut considérablement augmenter la vitesse de production par rapport à un processus de traduction impliquant uniquement des linguistes humains. Avec une puissance de traitement suffisante, on pourrait traduire des centaines de millions de mots en quelques jours seulement. Indépendamment du débat récent sur la question de savoir si l’on a atteint la parité entre la traduction automatique et la traduction humaine, en général, il peut y avoir des raisons de s’inquiéter de la qualité du résultat final. Une solution consiste à ajouter une étape de post-édition humaine, et éventuellement des étapes de révision supplémentaires, dans le cadre du flux de travail. L’intégration d’un processus de post-édition humaine réduit les délais d’exécution et permet également d’obtenir un niveau de qualité beaucoup plus élevé ainsi que d’identifier les points problématiques lorsque l’on utilise des MTAG.